I. Project Source Code
Project source code URL: (This project is not open source at present.)
II. Introduction
Personalized user behavior and cold starting data models are got to build different scoring strategies online, and the same as offline. With these strategies, specific data are selected from the offline recallable data source, and are filtered and ranked as results for the online recommendation. AB-Testing experiments are observed online.
III. Schemes
The process structure is as follows.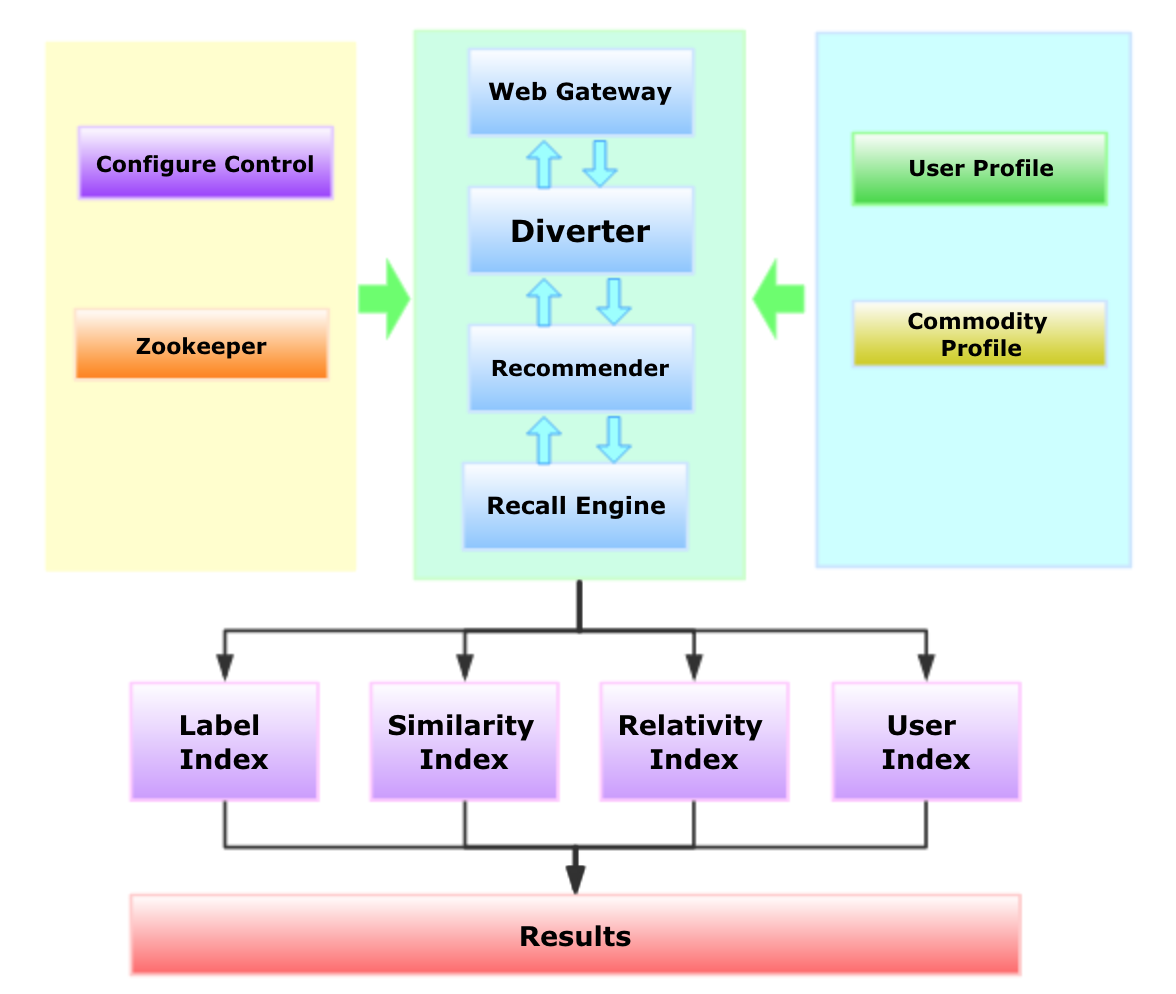
3.1 Parameters Parsing
It includes the parsing parameters in configuration files, such as user account, user configuration, and experimental configuration.
3.2 User Model Extraction
The models are obtained from various user behavior model services, such as real-time behavior model, long-term models as user profile, and some models trained by offline features.
3.3 Data Recall
The following steps are independent of each other and do not interfere with each other, so they can run in parallel.
Based on collaborative filtering, the nearest result sets of similar users and similar commodities are gained, and then data is filtered by rules to get the candidate set lists.
Based on cold start data, candidate sets are read from user profile and commodity profile, and then data is filtered by rules to get candidate set lists.
Based on the recall results of the specific algorithm (omitted here), the data is read from the database and filtered by rules to get candidate set lists.
3.4 Data Fusion and Ranking
The multi-model fusion is done, and the score weights are calculated, then the data are ranked according to the scores of different sets.
The quality score can also be gained by offline machine learning, and machine learning can also be used for online feature calculation.
3.5 Data Filtering
The ranked sets are filtered according to specific rules.
3.6 Data Alternation
According to different bucket-dividing strategies, the alternation of category, brand word and product word is carried out to ensure the diversity of the results.
3.7 Results Display
The results are gained and displayed.
IV. References
[1]…
[2]…
[3]…