I. Project Source Code
Project source code URL: (This project is not open source at present.)
II. Introduction
Generally speaking, the commodity classification is built according to categories, and it can be divided into three categories of different levels at most. However, such a classification is difficult to meet the purchase needs of users in specific situations. For example, commodities such as travel backpack, sports shoes, sports clothes, walking sticks, selfie stick do not belong to a category, but they may belong to a specific scene “outdoor hiking”, in that case, the selfie stick can be recommended to the user to satisfy the purpose of scene recommendation. Such scenarios summarized artificially usually exist generally and practically, and it has commercial value. Similarly, other scenario themes can be abstracted. In order to enrich the recall data system, the improved LDA topic model is used to implement scene recommendation.
The final goal is to cluster commodities across different categories to topic scene. Based on user’s click and order behaviors, the commodities are divided into many pairs or n-tuples as “scene”, and data are recommended for each other in the same scene. The data is processed by pig and python.
It is specified that:
1.The scene is a single, fine-grained, explicit theme;
2.The commodities of a scene are not all in a three-scale category, otherwise the scene is the same as the three-scale category;
3.There is sufficient vector distance between scenes;
4.The scene theme’s coverage is over 99% so that the buckets of data tuples are prevented from skewing seriously.
In the early stage, the number of scene themes designed artificially is 2000. Later, the number is 10000 by automatic data mining.
III. FP-Growth Scheme Based on Frequent Itemset
3.1 Data Acquisition
The most recent data of click and order are from user session. The latest data of user is extracted such as search, click, add cart and order, and combine these data into tuples of two to four, just as (click, order), (order, order), (search-word + cart, order). Then, the higher ranking combinations extracted by each method are regarded as the combinations with higher confidence. By collecting data for 30 days, the top N combinations with high frequency can be used as candidate set. The candidate sets of 3-4 months are used, and then the data of each month are intersected to get some sets.
3.2 Data Evaluation
Method 1: Randomly select 10% of the combinations from each method, and artificially evaluate the proportion of scenarios in the combinations.
Method 2: Choose one month order and some click sequences of proportional sampling as evaluation data.
These combinations are used to predict the evaluation data and to observe how much data can be matched, i.e. the recall rate of each method.
3.3 Recall Data Clustering and Marking
The similarity of these rule methods can be calculated for clustering. For example, the overlap degree of each element such as product-word, cid3, cid2, cid1 in the combination can be calculated, and these elements are then labeled artificially.
3.4 Conclusion
By analyzing the data, it can be found that if ordered by frequency, the product word combinations with frequencies more than 10 are concentrated in the daily use commodity categories of higher sales, such as “wet paper towel” and “shampoo”. After clustering, only about 400 combinations are found, and the distribution of them cannot cover most commodity categories. Thus another scheme can be considered to mine scene data.
At present, the automatic mining method based on frequency will result to the clusters concentrate to high-frequency purchased commodities. To ensure the coverage of topic scenarios, some scenes are defined artificially, and then the automatically mined data have been added to these scenarios to enrich these scenarios.
IV. Topic Model Scheme Based on LDA
4.1 Topic Classification System
From the previous data mining method based on frequent itemsets, it is found that the scenes of automatic mining are heavily clustered, and some distances of scenes are too close to each other. In fact, the user behavior is too little, too centralized, and there is lack of cold start data based on scene, resulting in serious skewing of data buckets.
So it is necessary to design a scene classification system from the top level view to reshape the scene data mined automatically. The current three-level classification system is not suitable for the current data completely. By establishing the classification system, on the one hand, the distribution of scenarios in the whole station commodities can be known, and the perception of scenarios can be built, on the other hand, it can ensure that the scenarios established would have a higher coverage for all the commodities in the future. The current classification system is mainly according to the second category, named “domain category-topic”. There are mainly 12 categories and about 200 scene topics.
At present, two methods are combined:
Method 1: Establishing the framework of scene classification system artificially, and filling in it with product words manually.
Method 2: Mining data automatically, finding the commodities user purchased, it can assign the data to the framework buckets defined artificially.
4.2 Automatic Data Mining
The top N combinations are picked as the candidate from these combinations extracted by each method. For example, the topic scene model “daily cleaning” can be extracted from the combination of bath lotion, shampoo, toothbrush and toothpaste.
But there are the following problems:
First, there are many repetitions of the scenes of four product word, and it needs to be merged. But at present, they cannot form a new topic scene after merging.
Second, scenes based on sku-level have too few skus and need generalization as well.
4.3 Structural Flowchart
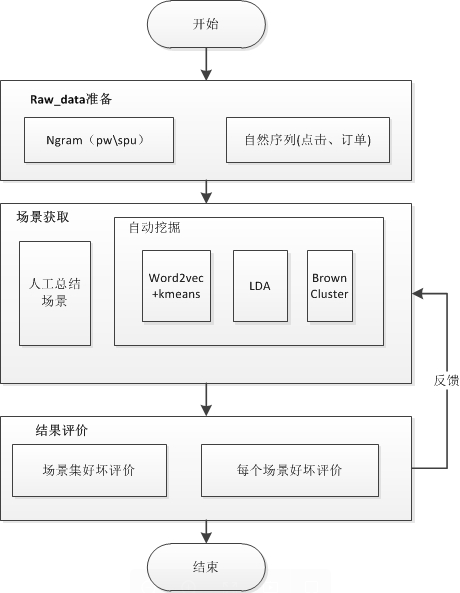
Stage 1: 2000 scenes are required.
Candidate combinations are put into existing first-level categories, and these data are artificially mapped to topics to define scenarios. And the commodities are gotten from the scene. At present, a scenario list is built manually, the next is to find the certain corresponding product words of the scene, and then mapped to sku.
Process: scene - > product word - > commodity sku.
Stage 2: 10000 scenes are required.
The cost of manpower is too high with the method at first stage. To consider another method, the solution is that it can cluster product word and commodity sku first.
① Calculate the distance between words
A) Calculate by word-embedding method;
B) Calculate with mutual information and Chi-square statistics;
② K-means++ Clustering
A) Guarantee that there are 5-7 product words in a cluster;
B) In the case of clustering, recall the SKU purchased by three days.
【Scene Automatic Mining】
It is considerable to cluster the four-tuple product words and SKU that satisfy thresholds.
① K-means
The distance between words is calculated by word-embedding and cosine similarity.
Advantages: Some results have been finished, and the effect of product word is good, which is worth trying, but the effect of sku is not good.
Disadvantages: It is not reasonable in theory, for there are similar scenes of product word.
Solutions: Review the results of product word artificially, and then mapped to sku.
② LDA
Advantages: Regard the scene as a topic, and then set the number of topics to get product word or sku.
Disadvantages: If four-tuple is considered as a sequence, however, LDA is not suitable for short text.
Solutions: A longer sequence such as a 7-day click sequence can be considered as a document, which ensures that a document has many duplicate items without the interference of stop words.
③ Brown-cluster
Advantages: It belongs to hierarchical clustering and can control the heap size of clustering after clustering.
Disadvantages: It is more effective for sequences and cannot guarantee for tuple data.
Solutions: A longer sequence is used to ensure that there are 5-7 product words in most clusters by controlling some thresholds. In the case of clustering, the commodity skus purchased within one month are recalled, and the sliding time window is 3-7 days. Finally, the skus of top 300 are selected as the recall data for each cluster.
4.4 Parameter Adjustment & Evaluation
(1) The scene sets are regarded as the evaluated objects. According to the scale of the whole scene set, the coverage of classification system, the minimum distance between scenes, and the average number of topic scene, the following evaluation indicators are defined.
(a) The total number of scenes and the number of classified scenes.
(b) The coverage rate of scene category, overall topic and category.
(c) The average number of topic scenes and the average number of a classified topic scenes.
(d) In the whole scene set, the minimum distance between scenes and the minimum distance between classified scenes.
(e) The average number of product words and skus in scenes and the average number of product words and skus in categories.
(2) A single scene is regarded as the evaluation object. According to the accuracy of scene, traffic of scene, sales volume and price range, the following evaluation indicators are defined.
(a) The accuracy of scene.
(b) The proportion of product traffic involved in the scene within a month.
(c) The proportion of sales involved in the scene within a month.
(d) Overall price range of products in the scene.
4.5 Online Interfaces
(1) Offline Data : was stored into 3 HBase tables
| TableName | Field1 | Field2 | Field3 | Field4 | Field5 |
|---|---|---|---|---|---|
| SceneTable | scene_id | scene_name | scene_sku | scene_image | scene_info |
| ListTable | scene_id | list_id | list_sku | / | / |
| ArticleTable | scene_id | article_id | article_text | / | / |
(2) Online Interfaces
(a) Input parameters of request : recommendation position id, user id, type=0. Returned results: 10 scene id, scene name, scene picture, scene description.
(b) Input parameters of request : recommendation position id, user id, type=1. Returned results: scene id, scene name, scene picture.
(c) Input parameters of request : recommendation position id, user id, scene id. Returned results: sku, list id, list sku, article id, article text.
4.6 Ranking Scheme of Recall Results
The ranking involves two parts: the ranking between scene modules and the ranking of sku in a scene. The ranking of sku in a scene can refer to traditional schemes of recommendation position ranking. In the meanwhile, the ranking can be considered from two perspectives, one is matching similarity of users and scene, the other is scene triggering.
4.6.1 Matching Similarity of Users and Scenes
(a) Unilateral feature of scene
Such features are these, within one week, the proportion of scene browsing, the proportion of users who browsing scenes, the proportion of sku sales volume in the scene, the proportion of users who ordered, and the repurchase cycle of scene.
(b) Bilateral features of User-Scene
| Action | Windows | Granularity/Attribute | Statistic |
|---|---|---|---|
| browse | Recently click: 1 time, 6 times, 10 times, 3 minutes, 10 minutes, 1 hour, 1day, 2 days, 3 days | scene | number, ratio |
| order | 1 day, 2 days, 1 week, 2 weeks, 1 month, 2 months, 3 months | scene | number, ratio |
| add-cart | 1 day, 2 days, 1 week | scene | number, ratio |
(c) Multilateral features of user-scenario-product words
Considering the problem of cold start. When the users do not have scene data, according to the coincidence degree of user’s recent behavior and scene product word, these scenes with top 5 coincidence degree can be gotten, whose IDs and scores can also be gained.
| Action | Windows | Granularity/Attribute | Statistic |
|---|---|---|---|
| browse | Recently click: 50 times | Confidence degree of scene | score |
| order | 3 days, 2 weeks, 1 month, 2 months, 3 months | Confidence degree of scene | score |
| add-cart | 1 day, 1 week | Confidence degree of scene | score |
4.6.2 Scene Triggering
The weight of product words in the scene can be considered.
V. Work Results
A patent paper entitled “Scene recommendation based on topic models” has been published.
VI. References
[1]…
[2]…
[3]…