I. Project Source Code
Project source code URL: (This project is not open source at present.)
II. Introduction
The offline profile data mainly include user profile, commodity profile, recallable source data information and user’s account information, etc. However, these data are stored in different database services, such as HBase, Redis, Hive tables, Memory Cache, and middleware data services encapsulated based on these underlying databases. Therefore, it is so inconvenient to query and integrate different data, even observe and debug data, in that case, the visual interface is required for offline profile data. So based on the Spring’s MVC structure, the java web system named “Recommendation Datum Query System (RDQS)” has been developed.
III. Architecture Design
The data logical hierarchical framework is designed as follows: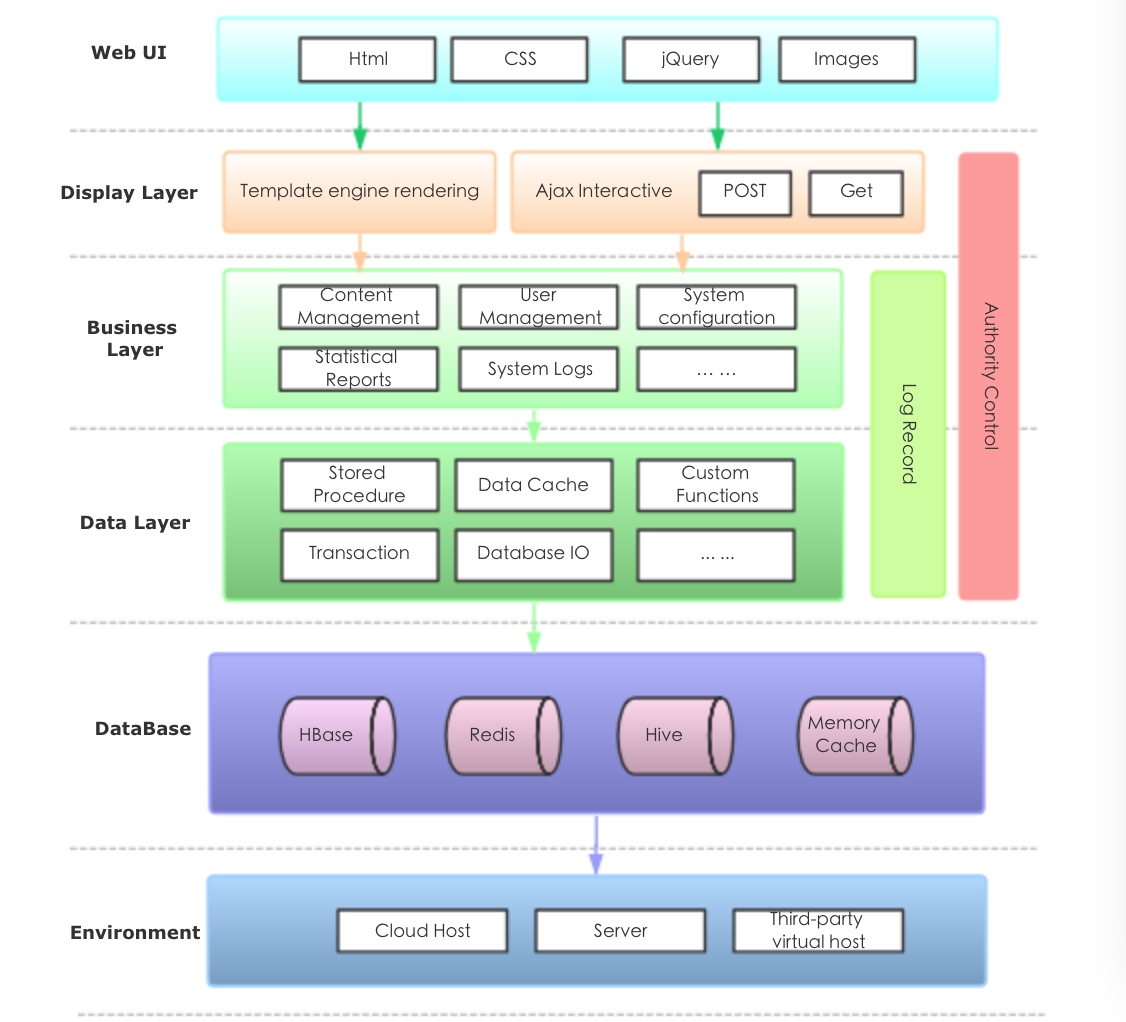
(1) Database Layer: It accesses to databases and data services, and preliminarily processes these data fetched from databases.
(2) Data Logical Layer: It is a data structure independent of the database, and it integrates data according to the business logic.
(3) Front-end Interface Layer: It focuses on the product user experience design (UED), and optimization of visual and operational experience effects.
IV. Back-end
4.1 Database Layer
First, data truncation. In order to prevent from returning results timeout because of get numerous data at one time, so generally, it is necessary to truncate the retrieved data to less than 200. In the meanwhile, the users need not view more data on the interface.
Secondly, concurrent data fetching. When the user choose to query several profile data at one time, the amount of data requested is large, it can usually as much as millions. Such data need to be loaded within 0.1 seconds, so that there is no obvious delay in human visual observation. Thus the parallel optimization is needed for fetching data logic.
Third, data preloading. By preloading the data previously read and frequently accessed to the cache, rather than getting data from databases each time, it can accelerate the query.
Fourth, data rolling loading. For declining the delay of data access, the back-end paging method is used to request to load data step by step. It actually only requests the data of the first page when the user browsing the first page, while the user moving to the second, it requests the back-end database again to retrieve the data of the second page.
Fifth, data formatting. This is mainly to make it convenient for front-end display.
4.2 Data Logical Layer
First, encapsulation of underlying data. According to the business logic, the data can be divided into four parts as user profile, commodity profile, recallable source data and user account information, and the retrieval index is developed for these parts. The user need to choose which catalog they required for their query, then they will get certain data.
Second, query of separate platform account such as user-id, uuid and sku-id. The mapping table of cross-platform accounts is added, and updated regularly. The data is read directly.
4.3 Data Display Layer
The interface for front-end to back-end interaction is provided, and the front-end and the back-end can send HTTP requests to each other for data interaction.
V. Front-end
It is based on JavaScript (jQuery) and Bootstrap. Because the system is not a large-scale system, and the front-end module has not been separated as a front-end subsystem at present. In fact, some sophisticated front-end framework such as AngularJS and React cannot meet the requirements currently, so it is sufficient to build some components with JavaScript directly.
5.1 Interference Reconfiguration
The interface reconfiguration is to better adapt to back-end data.
5.2 Front-end Componentization (Front-end Engineering)
Front-end engineering is a complex subject, from the simplest point of view, it is front-end componentization. A page is made up of separated parts, and these parts are independent with each other, which can be abstracted for subsequent reuse. According to function modules, the development files structure and division of team work are arranged easily, and there are more advantages to do following maintenance. It is better than according to the file catalogue. The topics about front-end engineering are detailed in my other series of blogs.
5.3 Search Function
It supports user to select different accounts to query data interactively. The user can choose from the dropdown menu to query with user-id, uuid and sku-id. It also supports keyboard up and down selection, the same applies to mouse click selection, then the requests are sent to background to return data. When inputting query content, it can pop up the drop-down menu automatically, and there are several suggestions matching for input content. By pressing the keyboard up and down keys, one can select in the following input prompts, and the selected items will automatically fill the text into the search input box. And the item can also be selected by mouse click.
The interactive selection scheme is shown in the following figure: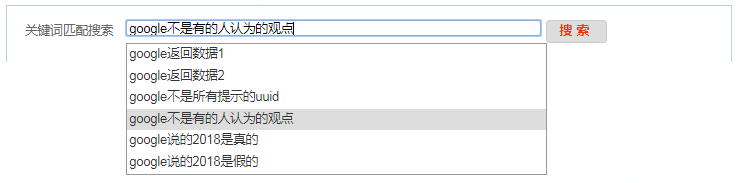
5.4 Multilevel Catalog Display
The hierarchical multilevel directory display is a three-level menu. When a catalog is selected, the data only for this catalog can be retrieved. It is similar to the general information retrieval system, so it is no necessary to elaborate on it.
VI. Other
It has been expanded to a unified data service platform, docking all offline data.
VII. Reference
[1]…
[2]…
[3]…