引言
基于文本挖掘的技术:对文本提取关键词后对其特征进行向量空间模型训练,之后进行文本分类/聚类,形成文章摘要和标签;或者利用特征向量生成模型用于排序;利用文本提取特征用作用户购买决策预测的技术,目前基于文本分类、文本挖掘的技术集中在文本标签提取、新词发现方法优化等。
一、概述
基于用户微信沟通文本提取用户特征,通过模型预测用户转化或购买决策的概率,并且可以通过新构建文本提取相应的个性化沟通话术,促进成交转化,从而提高用户下单转化率。
在文本挖掘领域,现有的技术主要集中在文本分析和标签生成,词向量模型为词嵌入模型,少有深度学习模型。结合文本挖掘技术,通过机器学习和深度学习的方法对文本表示进行改造,再结合机器学习模型对用户转化概率预测,能有效提高目标潜在用户的识别准确率、然后针对性采用相应策略沟通话术等。
二、技术方案
利用用户沟通文本挖掘的转化概率预测算法,基于用户微信沟通文本,区分不同学科粒度(英语、语文、思维),预测用户购买课程的转化率,计算是否转化系统课的转化率CVR。即基于用户文本特征的是否下单的二分类预测。
输入数据:user_id(用户id), content(原始文本), label(标签)
输出结果:user_id(用户id), cvr_score(预测概率分数), predict_label(预测标签)
其中,CVR预测分数范围(0,1)区间,并据此给出用户分层。
整体流程图如下:
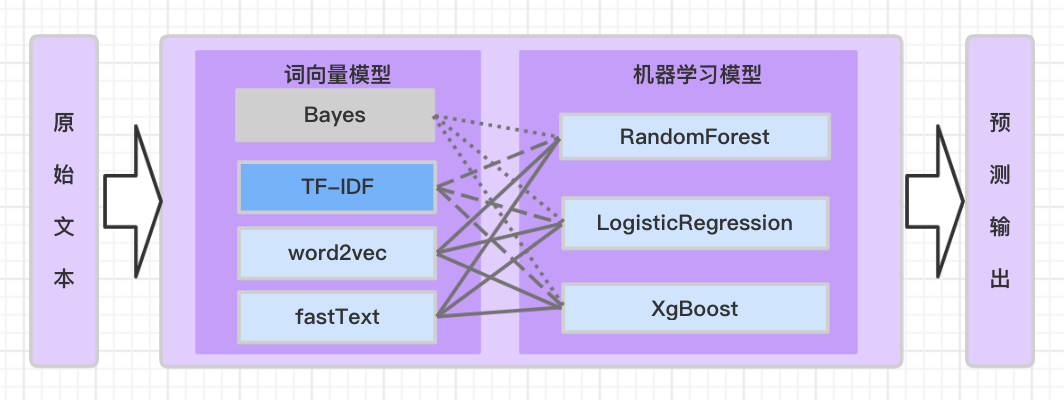
用户文本数据处理全流程架构图如下:
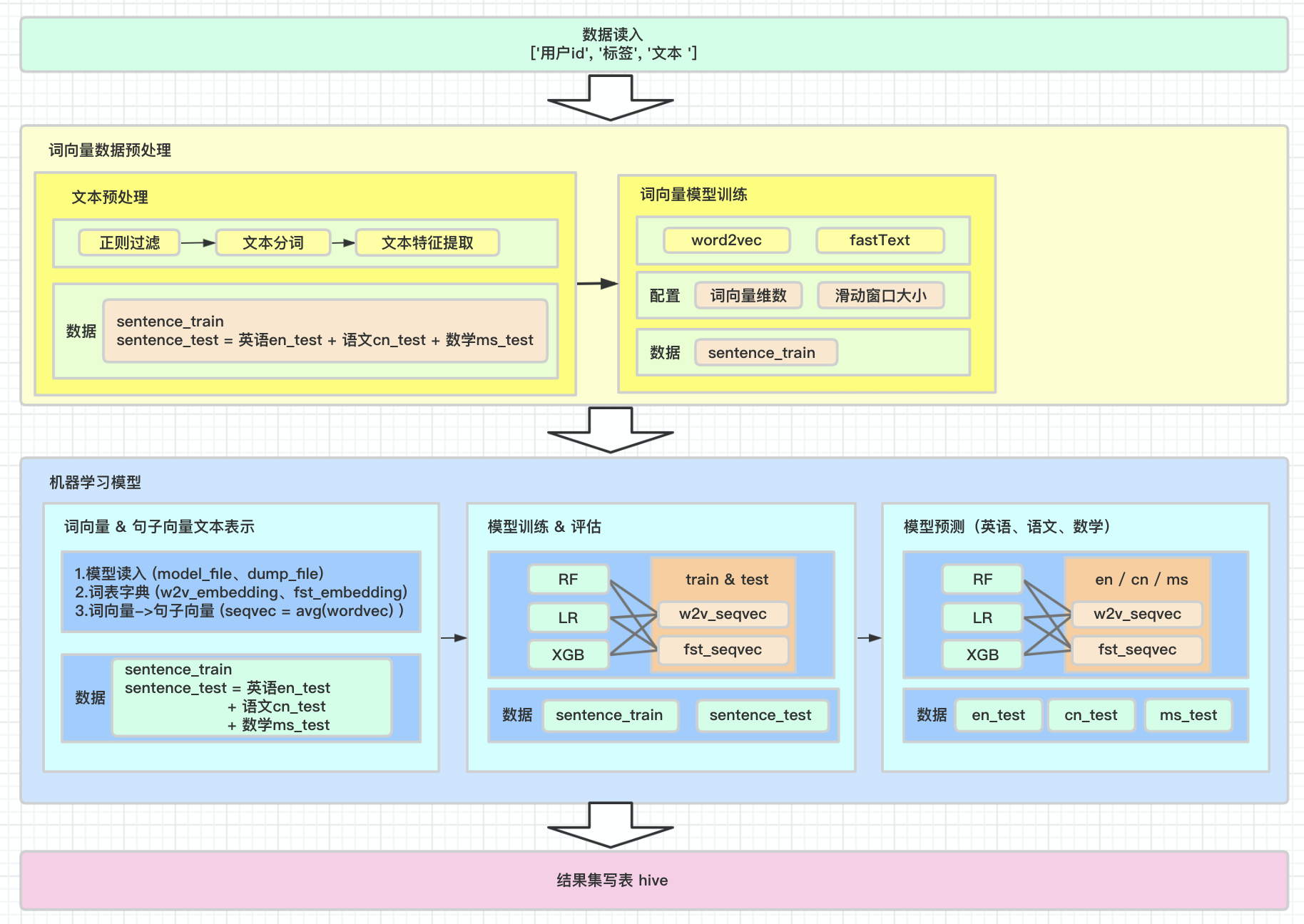
主要拆分为两大部分:第一,词向量模型部分,该部分主要是通过对原始文本进行特征提取得到文本的词向量表示,进而得到句子向量表示;第二,机器学习模型部分,该部分主要是用得到的句子向量矩阵,以结构化数据的形式输入,用机器学习模型,得到用户转化概率的预测分数。
模型训练集用全部学科的沟通文本进行训练,模型预测部分区分不同学科(英语、语文、思维)进行预测。
2.1.文本向量模型
对于定长时间窗口内,每个用户的文本按时间序列聚合为句子,考虑词序上下文关系,处理流程如下:
原始文本 文本句子集 文本词集 词向量&句子向量(特征) 转化率分数
content —> sentences —> words —> word_vector(feature) —> cvr_score
2.1.1.文本特征提取(词向量化)
根据用户微信沟通文本,提取用户文本特征。
和传统机器学习训练不同,直接用文本的分词结果、或者直接用词语表示,无法作为监督机器学习模型的输入格式,需要将词表示为定长维度的词向量,这样训练的特征维度可以采用固定值(此时词向量的每一维feature无实际意义)。
(1) 取定长时间窗口内的用户沟通文本,用户历史过去三个月的微信沟通文本;
(2) 每个用户user_id的沟通文本text按时间序列聚合为一行句子,考虑词序上下文关系,得到文本句子集合;
(3) 文本过滤:去除标点符号、特殊符号、数字、非法字符、表情包、链接;
(4) 文本句子分词:得到二元组2-gram、三元组3-gram、四元组4-gram、…;得到如下格式所示:
| user_id | label | sentence | words |
|---|---|---|---|
| user_id1 | label1 | sentence1 | [ word1, …, wordN ] |
| user_id2 | label2 | sentence2 | [ word1, …, wordM ] |
| … | … | … | … |
| user_idX | labelY | sentenceS | [ word1, …, wordT ] |
原始文本:(此处已经将用户在一定时间窗内的文本,按时间序列,聚合为一个长句子)

对每行句子正则过滤、分词,得到如下表示:(其中sentence为句子集合组成的数组)

2.1.2.由词向量(wordvec)生成句子向量(seqvec)
(5) 去除词频低于设定阈值的词;
(6) 去除停用词stop-words;
(7) 由词组得到词向量,采用word2vec和fastText词向量模型进行词向量模型训练,其中词向量维数采用固定长度,滑动窗口gram大小采用固定长度,上下文模型采用Skip-Gram或CBOW;得到的词向量分别为w2v_wordvec、fst_wordvec。如下所示:
| word | word_vector |
|---|---|
| word1 | [ feature1, …, featureN ] |
| word2 | [ feature1, …, featureM ] |
| … | … |
| wordN | [ feature1, …, featureT ] |
(8) 通过词向量生成句子向量。得到词向量表示后,整个句子的向量可以通过该句子中所有词向量求平均值得到,传统不需要训练的方法是句子向量=avg(词向量)。由此可以如下表示用户的文本特征:
| user_id | label | sequence_vector |
|---|---|---|
| user_id1 | label1 | [ seq_feature1, …, seq_featureN ] |
| user_id2 | label2 | [ seq_feature1, …, seq_featureM ] |
| … | … | … |
| user_idX | labelY | [ seq_feature1, …, seq_featureT ] |
通过调整词向量模型的部分参数:词组gram的滑动窗口大小、词向量维数,确定最优词向量模型参数组合。
【备注】
a) 还有其他通过词向量得到句子向量的方法,类似神经网络类的方法,详见其他文献参考。
b) 浅层语义模型(如word2vec)更关注词向量的产生,而预训练语言模型(高层语义模型)主要指能产生上下文相关的特征表示,能更好地捕捉上下文关系,使特征feature表示更精确,这直接关系到之后接入机器学习模型的训练数据形态,影响模型最终效果。本文由于目前关注词本身,故此处并未采用预训练模型。对于预训练语言模型,详见其他文献参考。
训练集句子向量表示:

2.2.机器学习模型训练
将用户沟通文本转化为可以用监督机器学习的句子向量特征表示后,用机器学习模型训练。此处接入随机森林(Random Forest)、逻辑回归(Logistic Regression)、梯度树(GBDT)模型。
如图1所示,单独对于每个词向量模型word2vec和fastText得到的句子向量w2v_seqvec、fst_seqvec依次输入不同的机器学习模型RF、LR、GBDT,通过和各个机器学习模型组合,分别预测用户下单/不下单的二分类概率输出。
三、优化方向
1.词向量部分仅从词本身的角度采用浅层语义模型,即仍然是基于词频统计(包含文本滑动窗口),提取的特征未能完全表示上下文特征信息表示。改进方向:可以用预训练模型,直接获取上下文相关特征表示,能更好地表征句子信息。
2.机器学习模型部分,此处是每次对接单个模型接入。
(1)考虑组合特征、上下文相关信息,输入模型特征未做特征交叉。迭代model版本可引入交叉特征。
(2)尝试模型融合。
3.引入隐层语义特征表示,而不仅仅是基于词本身作为的特征。