引言
联邦学习是一种加密的分布式机器学习技术,对于一些对用户隐私数据保护要求比较高、样本少量、特征少量的场景,若需要训练大规模机器学习模型,此时需要借助第三方媒介来获取填充特征,但是用户隐私数据却又不能公开,所以联合建模技术就是为了解决这种问题而提出。
一、概述
1.技术领域
主要应用方向涉及互联网/在线教育中的数据联合建模、用户深层漏斗转化率预估等领域。
2.业界现状
对于互联网/在线教育中的数据联合建模和深度转化率预估,一些业界常用的现有技术如下:
1.基于联邦学习的分布式训练技术,应用于区块链、医疗数据建模、个性化搜索推荐,采用传统的类似逻辑回归等机器学习方法,数据样本在生成过程和传输过程分布在各个不同参与方,保证数据安全共享。
2.现有技术对梯度进行压缩,以减小网络传输开销。客户端训练初始模型得到梯度后进行量化处理,训练后得到更新的梯度发送给服务端,以此进行梯度数据交互,期间过程中对梯度压缩保证不失真,保证结果的安全性和数据私密性。
现有技术存在的问题:
现有技术基本采用传统机器学习模型的训练方法,对用户深度等转化数据建模的方法需要深度学习等方法结合具体场景进行建模。现有部分技术在训练过程中采用了深度学习模型,但并未进行分层架构处理,所有参数在每次训练全部更新,计算量较大,难以复用。且尚未在用户深度转化率预估方面,有类似基于深度学习的参数传播方法建模技术存在。
3.技术问题
教育行业属于对用户隐私数据敏感的行业,一个完整的用户成交转化漏斗流程如下:用户通过和辅导老师沟通后,购买试用体验课,然后购买正价系统课。
第一,数据层面需要深度转化指标。对于教育行业,相比用户的试用体验课购买转化率,实际核心指标更关注用户的正价系统课购买转化率,此为深度转化模型。但用户深度正价课的成交数据为敏感保密数据,为营收核心指标,不能提供给第三方媒体平台。另外,投放方能获取到用户的特征非常稀疏,但同一用户在其他第三方媒体平台上可能会积累大量行为特征,投放方需要利用媒体平台的这些特征进行模型训练以预测用户深度转化率,同时需要用户数据直接在投放方的本地环境下(不出数据库),进行联合建模训练。
第二,联合建模若仅利用传统机器学习模型预估购买转化率CVR等指标,存在建模学习数据较浅的问题,需要深度模型训练。
为了解决以上问题,我们给出了一种新的技术方案,可以有这些收益:
1.数据隐私保护。利用该分布式机器学习/深度学习建模技术,投放方和媒体方的各自数据都可以在本地私有云上完成共建模型训练,防止敏感数据泄露。
2.通过联邦学习方式训练深度转化率deepCVR,即deepCVR=正价系统课购买人数÷使用体验课购买人数,该影响因子用以调整投放定价公式,直接对线上流量做实时预估,对eCPM的计算做出调整,从而优化平衡客户引流和投放。
3.从计算广告角度,作为广告主投放信息,对接各个第三方媒体平台,综合利用各个媒体平台用户公有特征,丰富了特征池,模型训练效果更优。
二、技术方案
整体架构图如下:
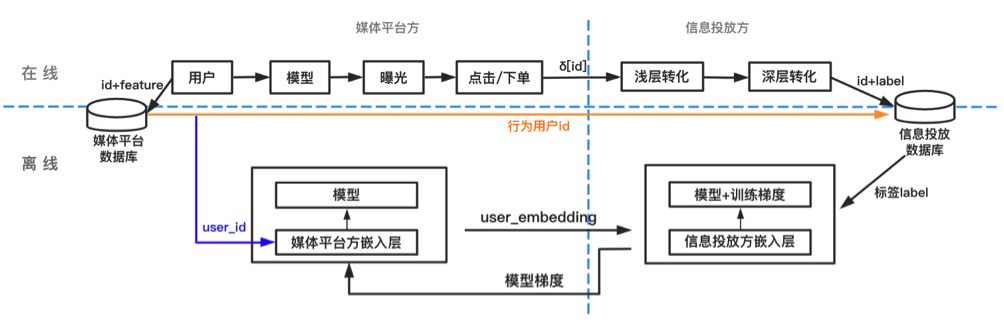
整个模型训练过程中,数据传输的交互流程图如下:
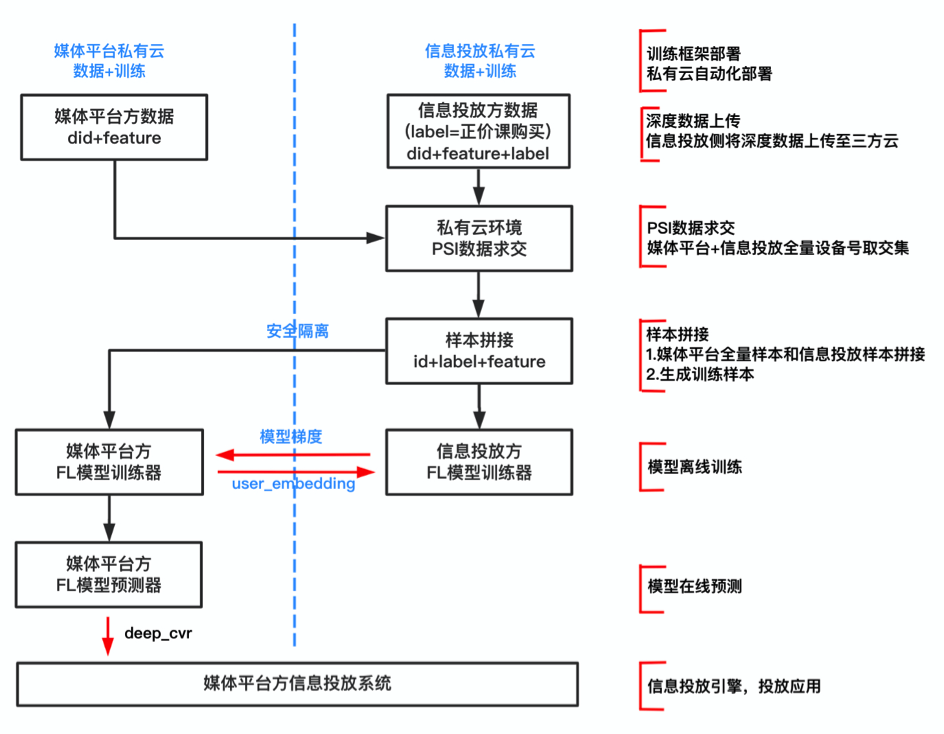
数据交互过程中,媒体平台侧的样本加密数据(账号id+特征feature)和信息投放方的样本加密数据(账号id+特征feature+标签label),在信息投放方的私有云环境上进行PSI安全数据求交运算;然后在信息投放方本地的私有云上进行样本拼接;拼接后回传给媒体平台方,媒体平台方和信息投放方在各自私有云上进行联邦学习模型训练;深度转化deepCVR模型预测在媒体平台侧进行,最后进入信息流投放系统进行投放应用。
主要步骤如下:1.训练框架部署;2.数据上传到私有云;3.PSI安全数据求交;4.样本拼接;5.模型离线训练及评估;6.模型在线预测;7.在线投放智能定价;
1.训练框架部署
训练框架用于数据网络通信、数据安全交互、模型训练等。信息投放侧在自己私有云/集群上安装并部署训练框架,媒体平台方合作协助支持。框架部署完成后,双方上传小量样本测试数据并开放对外授权,此样本数据用以调通训练流程。
正式模型训练和模型推理的计算机器资源,包括机器CPU核数、内存大小、硬盘大小、网络通信带宽、通信开放的HTTP和GRPC端口,按实际训练样本的数据量预估,保证能在特定的小时数之内,完成后续的数据求交、模型训练、模型推理等过程。
2.数据上传私有云
信息投放方和媒体平台方各自的数据会单独上传到各自私有云数据库,所有参与训练的用户id或设备号id均进行hash后md5加密处理,训练时直接对加密id和特征进行训练。
信息投放方的数据如下,需要标注是否下单标签,下单日期,而特征则非必要;同时,信息投放方仍然可以利用用户画像、课程、购买力等基础特征融合到数据中。
| encoded_user_id | label | order_date | feature |
|---|---|---|---|
| 加密用户id | 下单标签(必选) | 下单日期(必选) | 特征(可选) |
媒体平台方的数据如下,不需要是否下单标签。
| encoded_user_id | feature |
|---|---|
| 加密用户id | 媒体全域特征(必选) |
双方数据定期批量更新的方式同步到各自私有云中,参与后续模型训练。
3.PSI安全数据求交
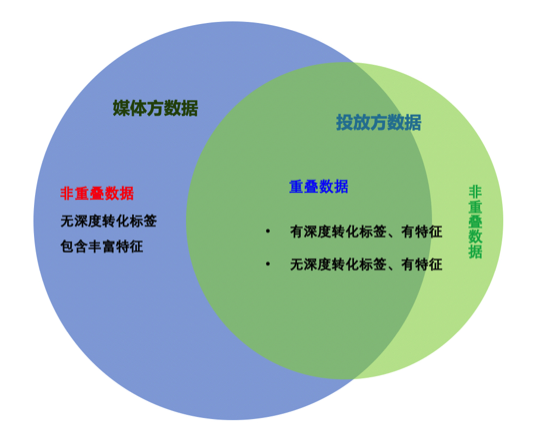
对信息投放方提供的用户id和媒体平台侧提供的用户id取交集,观测样本的重合度。一般地,对于共有部分的数据,可以直接进行后续的样本特征拼接,参与后续模型训练;对于各自非共有部分的数据,则不参与训练。
通常情况下,媒体平台侧拥有海量用户id,而信息投放方的用户id相对而言则较少,如果重叠用户占信息投放方的用户id的60%~90%以上,则认为是有效的,可以进行后续的模型训练。如果双方用户id重叠程度过低,信息投放方需要舍弃大部分用户id不能参与模型训练,则需要另外修改数据。
信息投放方的数据分为以下两种:第一,含有是否下单标签,有少部分特征,比如用户的行为、画像、基本属性等。有标签的部分数据是用户已经产生了是否下单行为;第二,存在相当一部分用户,没有是否下单行为,即仅已经激活注册,但没有深度行为,但有少部分行为/画像/属性等特征。
媒体平台侧的海量数据,主要提供丰富的特征,比如电商、社交媒体、广告、内容等,没有用户针对特定场景的行为标签,这些标签需要信息投放方根据具体应用场景进行标注正负样本。
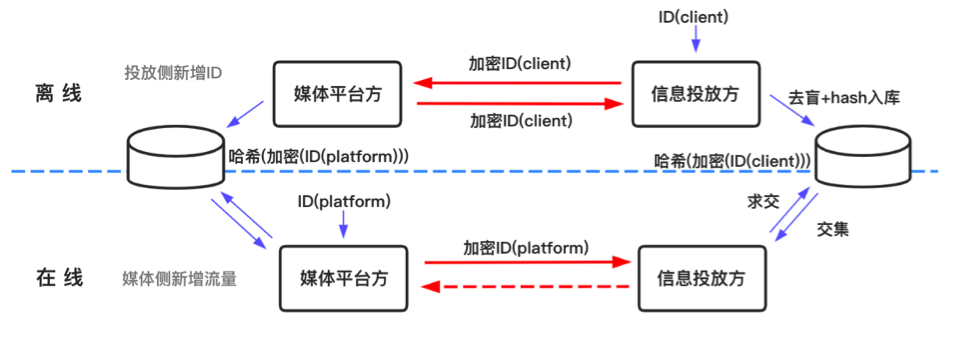
数据求交过程如下:媒体平台侧的加密用户id,同步到信息投放方的数据库中,和信息投放方的加密用户id求交集。
4.样本拼接
对数据求交后的id拼接训练数据。由于数据加密,用户id、下单标签label、特征feature不存在泄露问题,即信息投放方不会将用户及其深度下单转化数据、手机号等敏感信息,提供给媒体平台侧。
对于重叠部分用户id,每条样本格式为:加密用户encoded_user_id、下单标签label、下单日期order_date、媒体全域特征features+投放方特征feature。后续模型预测此部分特征维度。
对于非重叠部分用户id,主要集中在媒体平台方,每条样本格式为:加密用户encoded_user_id、下单标签label、下单日期order_date、媒体全域特征features。后续模型预测此部分特征维度。
5.模型离线训练及评估
联邦学习模型训练支持机器学习模型和深度学习模型,机器学习模型例如线性回归、逻辑回归、梯度树模型等。深度学习模型主要为NN深度神经网络。
训练过程中,采用分布式的方式,信息投放方和媒体平台方各自在单独的本地私有训练机器上进行单独的模型训练(机器已部署训练框架),期间机器间仅交换模型每次迭代更新所需要的梯度,其中传输的梯度已加密传输。整个交互过程中没有明文信息,不能反解。依据同态加密原理,加密后再训练和训练后加密的结果相同,故可以用加密后再训练的结果替代训练后加密的方式。
5.1.基于机器学习的模型训练
采用梯度树模型GBDT进行训练,预测用户是否下单,为二分类模型。
5.2.基于深度学习的模型训练
5.2.1.联邦深度学习架构
模型为NN深度神经网络,仍然训练二分类。基于深度模型的联邦训练,每次更新深度网络的一个子网络,同时更新前向/后向传播过程。
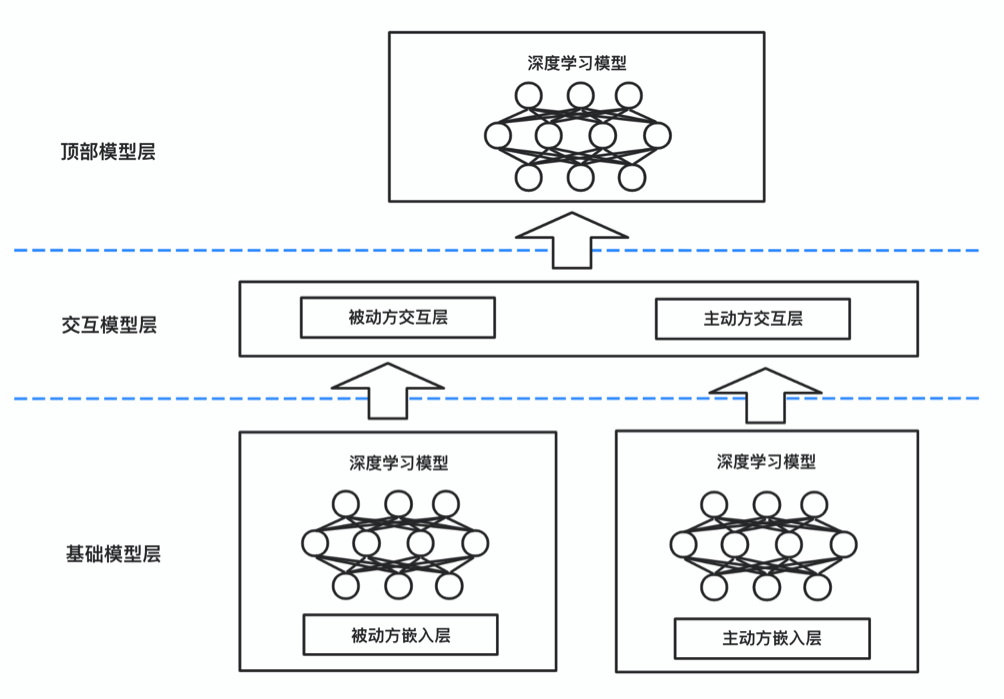
联邦学习NN模型整体分为三层:基础模型层(Basic Model Layer)、交互模型层(Interactive Model Layer)、顶部模型层(Top Model Layer)。有标签的提供方为主动方(Active Party),没有标签的提供方为被动方(Passive Party)。
基础模型层在主动方和被动方都存在,并且各自维护单独一套DNN深度神经网络训练的基础模型,凡是包含特征的参与方都会有基础模型层;
交互模型层,若主动方没有特征,那么交互模型层仅含有被动方的交互模型,若主动方有特征,那么交互模型层包含主动方的交互模型和被动方的交互模型,主动方获取被动方传输过来的加密梯度、以及基础模型层的其他输出,融合本方模型更新需要的梯度参数之后,更新整体模型参数,以便后续训练,交互模型层的输出,经过激活函数传到顶部模型层;
顶部模型层只在主动方存在,此为类似应用层,主要计算模型的损失,并把误差反向传播回去。训练后输出最终模型预测得分结果。
在整个联邦深度学习训练过程中,需要在主动方和被动方之间每次相互计算和传播梯度,多次循环迭代后直至模型收敛,期间的计算开销和通信开销较大。我们在整个算法过程在此基础上作了一些改进,主要包括:(1) 对需要交互传输的参数进行分层优化,大部分需要计算的参数(包括梯度)会集中到交互模型层计算;(2) 梯度计算优化和加速方法,每次迭代均需要计算梯度和加密梯度,然后再相互传输,通过优化梯度的计算过程、多次小批量并行计算,加快训练迭代收敛速度,同时减少通信传输开销。
5.2.2.分层网络优化
整个训练过程纵向拆分为基础模型层、交互模型层、顶部模型层。基础模型层只关注数据嵌入,之后接入的深度模型可以为任意NN模型;交互模型层关注相互传输的参数,每次迭代过程中,更新对训练值$\alpha$的权重$W$和偏置$\epsilon$。
深度神经网络的训练结构,基础模型层、交互模型层、顶部模型层的模型都各自独立训练而互不干扰,每层模型有更好的可拓展性。基础模型层的DNN模型可以替换为其他NN深度模型,而真正联邦深度学习的重点则在关注交互模型层的数据安全性。加密和解密过程只存在于交互模型层,不会在整个神经网络中,从而提高建模效率。
5.2.3.前向/反向传播、梯度计算过程
一般地,深度学习的前向/后向传播过程如下:
(1) 计算,其中为预测目标函数值,$W$为权重矩阵,$\alpha$为训练值,$\epsilon$为偏置矩阵(此处为随机噪声扰动值)。
(2) 计算,求差值的绝对值,其中为真实值,为预测值,残差$\delta$为损失值$loss$;
(3) 计算, 用残差$\delta$和偏导相互作算子乘积;
(4) 计算,此处激活函数可以为$softmax$、$tanh$、$ReLU$等函数,具体依模型不同而激活函数不同;
(5) 计算,以上过程得到的当前$t$时刻的值保存,继续用于计算在下一个$(t+1)$时刻的,后续依次循环迭代。
深度学习的梯度下降过程如下:
(1) 计算权重$W$和偏置$\epsilon$的偏导,计算目标函数$L_{N}$的对数似然梯度。
(2) 依次循环计算$(t-1)$时刻的权值和偏置的偏导。
(3) 更新所有权值和偏置等网络参数。
在此联邦分布式训练的情景下,我们针对该场景作了参数拆分,分发到不同分布式训练方上进行训练。并且,参数在训练过程中是明文,但在传输过程中需要加密,因此需要拆分一部分参数用于加密(如训练因子$\alpha$、偏置噪声$\epsilon$),而另一部分参数则不需要加密。整体训练步骤如下,分为前向传播过程和反向传播过程。
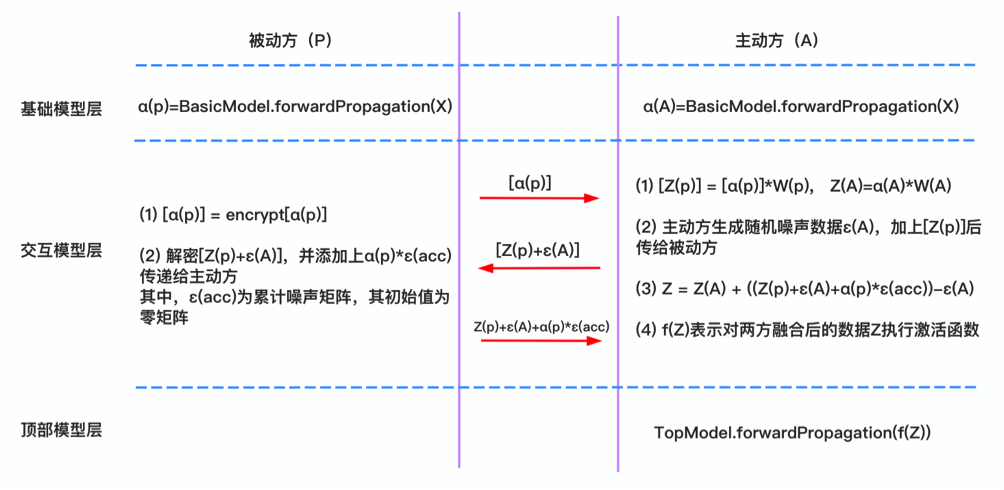
前向传播过程中,基础模型层主动方和被动方分别计算前向传播梯度;交互模型层中,被动方对梯度加密后传输给主动方,主动方计算梯度加权系数,生成随机噪声,加上偏置后回传给被动方,被动方解密数据,计算累计噪声矩阵并乘上调整因子,然后传给主动方,主动方用激活函数计算后传给顶部模型层;顶部模型层中计算前向传播梯度。
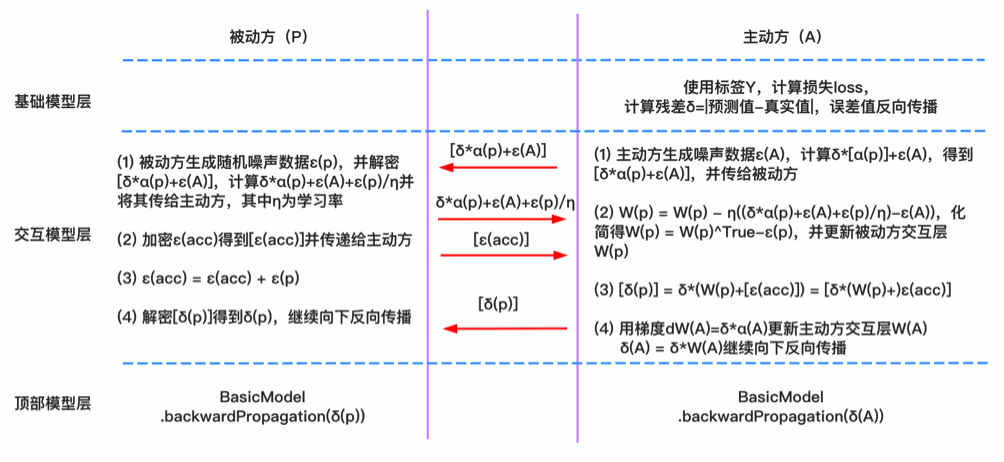
反向传播过程中,在顶部模型层,主动方利用标签计算损失$loss$,即预测值和真实值的绝对值之差,得到残差$\delta$;交互模型层中,主动方生成噪声数据并乘以因子后传给被动方,被动方生成随机噪声数据,加和后除以学习率$\eta$,加密后传给主动方,主动方依据公式加权计算权重,然后更新被动方交互层,被动方解密,然后继续向下反向传播;基础模型层计算后向传播梯度。
5.3.模型评估
后续模型迭代优化,仍然以二分类的AUC等离线指标作为离线评估标准。原始标签数据一般在主动方提供,所以模型评估部分只在主动方进行。
6.模型在线预测
预测投放价格,进行灰度或全量的流量实验。
灰度小流量实验分为:空白组、对照组、实验组。每个组之内细分不同小组实验,切分对应流量;灰度实验效果稳定后,逐步切分全量实验。
在线灰度实验组划分如下:
| 实验组 | 小流量组 | 实验 |
|---|---|---|
| 空白组A | a1 | base_model_1 |
| a2 | base_model_2 | |
| a3 | base_model_3 | |
| 对照组B | b1 | model_1 |
| b2 | model_2 | |
| b3 | model_3 | |
| 实验组C | c1 | deep_model_1 |
| c2 | deep_model_2 | |
| c3 | deep_model_3 |
7.在线投放智能定价
对于用户深度转化率,从引流体验课,到系统课的价格预估公式。
投放定价公式如下:
其中,$eCPM$为每千次展示获得广告收入,该指标以衡量广告投放计费效果;$oBid$为广告转化出价;$pCTR$为预估点击率;$pCVR$为预估转化率;为模型输出结果即预估深度转化率;$f(*)$为扰动函数。
在线实验评估标准为:正价系统课成交数(deep_convert)提高、正价系统课成交率(deep_cvr)提高、信息投放方的投入产出比(ROI)提高。通过动态因子调整正价系统课的价格范围,达到整体最优化。
三、小结
相比现有技术,新的学习算法提出的方案:
1.采用分布式联邦训练和深度模型,得到用户深度转化率的评估,同时在训练过程中数据加密传输,有效防止用户敏感数据泄露,保证数据的安全性。
2.将分布式模型训练分层拆分,单独对交互模型层的参数进行优化,其余层的模型具有灵活可扩展性,框架结构可复用以便于多次实验迭代。
3.对梯度计算进行优化,小批量进行梯度更新,减小网络通信传输开销,加快分布式训练收敛速度。
4.投放定价公式用模型训练的private_deep_cvr权重因子修正,动态调节价格、动态修正eCPM数值,多次实验表明能带来较好的优化效果。
四、名词解释
1.联邦学习(Federated Learning):全称”安全联合传输学习“(Secure Federated Transfer Learning),实质是一种加密的分布式机器学习技术,参与各方可以在不披露底层数据和底层数据的加密(混淆)形态的前提下共建模型,主要应用于对用户隐私数据敏感的场景。模型训练过程中,数据加密传输,特征和样本均在加密后拼接,然后在公有云上训练和预测,得到预测结果数据,解密后返回给各方,训练过程完全透明。主要用于解决行业间联合建模的样本重叠少、特征重叠少、两者均重叠少等问题。
这种技术的参与各方可以在不披露底层数据和底层数据的加密(混淆)形态的前提下共建模型。主要应用在金融领域的风控模型、用户信用评级模型,金融科技公司作为数据服务商,和第三方公司如银行/证券/保险/券商等合作数据建模。除了金融,目前在电商/教育/电信等对用户隐私数据敏感的行业也有应用。
2.PSI数据求交(Private Set Intersection,隐私保护集合交集):多方数据求交集,找出共同样本,然后数据在各自的第三方云上完成加密,加密之后用于模型训练。
3.同态加密:一种密码学技术,同态加密后的数据经过模型训练得到结果再解密,和用同一种方式经过非加密模型训练得到的结果相同。