一、概述
TBB指令集, Threading Building Blocks(Intel TBB):英特尔发布,使用标准 ISO C++代码支持可扩展并行编程的库。不需要特殊的语言或编译器,可扩展数据并行编程。完全支持嵌套并行性,可从较小并行组件构建较大并行组件。使用该库需要指定任务而非线程,并让库以有效的方式将任务映射到线程上。
该库在以下方面与典型的线程包/线程池不同:
- 指定逻辑并行而不是线程。
- 以线程化为目标,以提高性能。
- 兼容其他线程包。
- 强调可扩展的数据并行编程。
- 依赖泛型编程。
二、TBB并行指令集函数
1.并行算法;2.任务调度;3.并行容器;4.同步原语;5.内存分配器;
TBB基础函数
1.parallel_for:并行方式遍历一个区间。
2.parallel_do和parallel_for_each:将算法应用于一个区间。
3.parallel_reduce:类似于map_reduce,先将区间自动分组,对每个分组进行聚合(accumulate)计算,每组得到一个结果,最后将各组的结果进行汇聚(reduce)。
这个算法稍微复杂一点,parallel_reduce(range,identity,func,reduction),第一个参数是区间范围,第二个参数是计算的初始值,第三个参数是聚合函数,第四个参数是汇聚参数。
这数组求和例子就是先自动分组然后对各组中的元素进行聚合累加,最后将各组结果汇聚相加。
4.parallel_pipeline:并行的管道过滤器数据流经过一个管道,在数据流动的过程中依次要经过一些过滤器的处理,其中有些过滤器可能会并行处理数据,这时就可以用到并行的管道过滤器。举一个例子,比如我要读入一个文件,先将文件中的数字提取出来,再将提取出来的数字做一个转换,最后将转换后的数字输出到另外一个文件中。其中读文件和输出文件不能并行去做,但是中间数字转换环节可并行。parallel_pipeline的原型:
第一个参数是最大的并行数,可以通过&连接多个filter,这些filter是顺序执行的,前一个filter的输出是下一个filter的输入。
第一个filter生成数据(如从文件中读取数据等),第二个filter对产生的数据进行转换,第三个filter是对转换后的数据做累加。其中第二个filter是可以并行处理的,通过filter::parallel来指定其处理模式。
5.parallel_sort:并行排序。
6.parallel_invoke:并行调用,并行调用多个函数。
TBB任务
task_group:表示可以等待或者取消的任务集合。
三、加速版ORB-SLAM3-FAST
已有的开源项目:https://github.com/hellovuong/ORB_SLAM3_FAST ,by hellovuong,at 2022.1。其不是直接加载for循环上的parallel_for,SLAM3_FAST框架是在图像的特征提取和后端优化部分做了tbb加速, 目前支持“TUM-VI和EuRoC”的“单目+双目”数据集。
实测,30s的Mono-TUM数据集,时间=0.02s数量级,Fast版本比Orb-Slam3原生版本确实都快0.002s左右,
四、TBB加速ORB-SLAM3
1.改造方法
(1)代码加速:parallel_for/parallel_reduce/parallel_invoke,修改并行计算模块:
OrbExtracter.cc, computeKeyPointsOctTree(); DistributeOctTree(); computeOrientation();
OrbMatcher.cc, SearchByProjection(); ComputeThreeMaxima(); SearchForInitialization();
Optimizer.cc, PoseOptimization().lock()/mono()/right-fisheye()/stereo();
Frame.cc, ComputeStereoMatches(); UndistortKeyPoints();
KeyFrame.cc: KeyFrame(); UpdateBestCovisibles(); TrackedMapPoints();
KeyFrameDataBase.cc: -
Map.cc: -
MapPoint.cc: - ComputeDistinctiveDescriptors();
LocalMapping.cc: searchInNeighbors(); KeyFrameCulling(); InitializeIMU();
LoopClosing.cc: deleteCommonRegionsFromBow();
System.cc: -
Tracking.cc, Track(); CreateInitialMapMonocular(); TrackWithMotionModel(); TrackLocalMap();
CreateNewKeyFrame(); SearchLocalPoints(); UpdateLocalKeyFrames();
(2)算法加速:前端(图像特征提取并行化)/后端优化/回环检测;
2.数据集
单目mono、单目IMU。共10个数据集,具体如下:
- mono_tum1
- mono_tum2
- mono_tum_vi_room4
- mono_tum_vi_slides1
- mono_euroc_MH01
- mono_euroc_MH03
- mono_imu_tum_vi_room4
- mono_imu_tum_vi_slides1
- mono_imu_euroc_MH01
- mono_imu_euroc_MH03
3.统计指标
按以下三个指标统计绝对时间、提速率。
- totalTime – 总运行时间
- medianTrackingTime – 轨迹中位数时间
- meanTrackingTime – 轨迹平均时间
注:
4.绝对时间统计
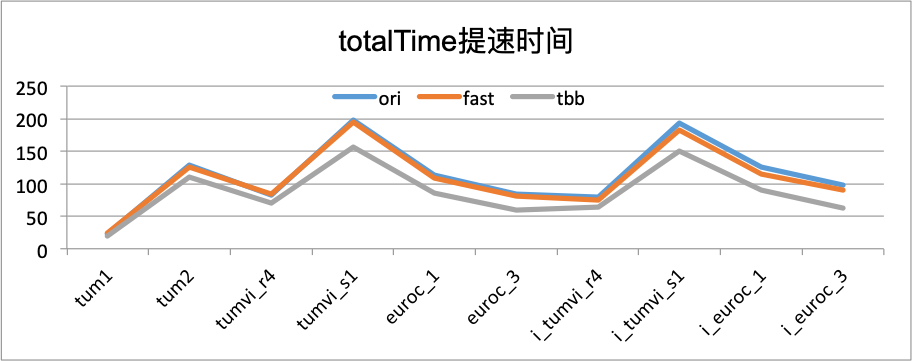
| totalTime | ori | fast | tbb |
|---|---|---|---|
| mono_tum1 | 22.9099 | 20.3967 | 18.819 |
| mono_tum2 | 128.491 | 116.23 | 110.91 |
| mono_tum_vi_room4 | 82.30296326 | 74.69300079 | 69.7 |
| mono_tum_vi_slides1 | 198.2973328 | 184.109024 | 156.94 |
| mono_euroc_MH01 | 113.8627319 | 98.12454987 | 84.973 |
| mono_euroc_MH03 | 83.69143677 | 70.68492126 | 59.8 |
| mono_imu_tum_vi_room4 | 79.43052673 | 64.13159943 | 64.208 |
| mono_imu_tum_vi_slides1 | 192.7673187 | 173.0284576 | 150.48 |
| mono_imu_euroc_MH01 | 125.3083267 | 104.5439606 | 90.488 |
| mono_imu_euroc_MH03 | 97.23898315 | 80.485672 | 62.913 |
| medianTrackingTime | ori | fast | tbb |
|---|---|---|---|
| mono_tum1 | 0.0246596 | 0.0229959 | 0.02178 |
| mono_tum2 | 0.0225559 | 0.0210467 | 0.020612 |
| mono_tum_vi_room4 | 0.031520639 | 0.029292193 | 0.0289 |
| mono_tum_vi_slides1 | 0.031224145 | 0.028130215 | 0.025574 |
| mono_euroc_MH01 | 0.028075576 | 0.024197916 | 0.021836 |
| mono_euroc_MH03 | 0.027769892 | 0.024874028 | 0.020141 |
| mono_imu_tum_vi_room4 | 0.030900763 | 0.025430075 | 0.025349 |
| mono_imu_tum_vi_slides1 | 0.030611012 | 0.026431446 | 0.024964 |
| mono_imu_euroc_MH01 | 0.031929269 | 0.025167587 | 0.022284 |
| mono_imu_euroc_MH03 | 0.031767674 | 0.023637912 | 0.021577 |
| meanTrackingTime | ori | fast | tbb |
|---|---|---|---|
| mono_tum1 | 0.0287092 | 0.0263192 | 0.023583 |
| mono_tum2 | 0.0247957 | 0.0223593 | 0.021404 |
| mono_tum_vi_room4 | 0.036940288 | 0.034013015 | 0.031284 |
| mono_tum_vi_slides1 | 0.035524424 | 0.032774099 | 0.028116 |
| mono_euroc_MH01 | 0.030924153 | 0.027365711 | 0.023078 |
| mono_euroc_MH03 | 0.030996829 | 0.027883305 | 0.022148 |
| mono_imu_tum_vi_room4 | 0.035651043 | 0.03027271 | 0.028819 |
| mono_imu_tum_vi_slides1 | 0.034533735 | 0.030789048 | 0.026958 |
| mono_imu_euroc_MH01 | 0.03403268 | 0.029109169 | 0.024576 |
| mono_imu_euroc_MH03 | 0.036014438 | 0.031513211 | 0.023301 |
5.提速率统计
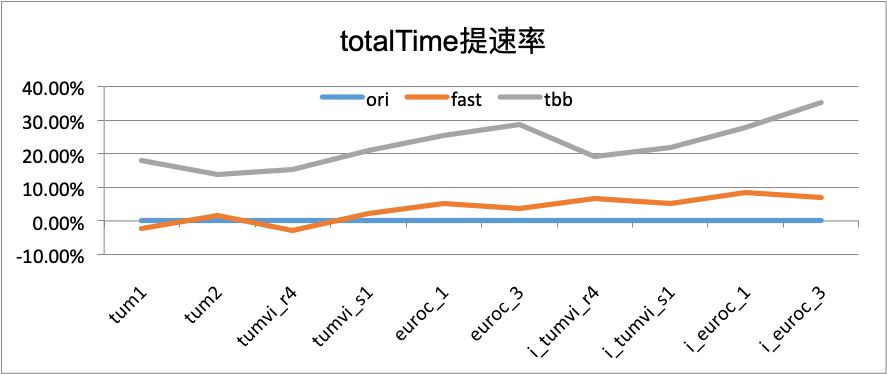
| totalTime | ori | fast | tbb |
|---|---|---|---|
| mono_tum1 | 0.00% | 10.97% | 17.86% |
| mono_tum2 | 0.00% | 9.54% | 13.68% |
| mono_tum_vi_room4 | 0.00% | 9.25% | 15.31% |
| mono_tum_vi_slides1 | 0.00% | 7.16% | 20.86% |
| mono_euroc_MH01 | 0.00% | 13.82% | 25.37% |
| mono_euroc_MH03 | 0.00% | 15.54% | 28.55% |
| mono_imu_tum_vi_room4 | 0.00% | 19.26% | 19.16% |
| mono_imu_tum_vi_slides1 | 0.00% | 10.24% | 21.94% |
| mono_imu_euroc_MH01 | 0.00% | 16.57% | 27.79% |
| mono_imu_euroc_MH03 | 0.00% | 17.23% | 35.30% |
| medianTrackingTime | ori | fast | tbb |
|---|---|---|---|
| mono_tum1 | 0.00% | 6.75% | 11.68% |
| mono_tum2 | 0.00% | 6.69% | 8.62% |
| mono_tum_vi_room4 | 0.00% | 7.07% | 8.31% |
| mono_tum_vi_slides1 | 0.00% | 9.91% | 18.10% |
| mono_euroc_MH01 | 0.00% | 13.81% | 22.22% |
| mono_euroc_MH03 | 0.00% | 10.43% | 27.47% |
| mono_imu_tum_vi_room4 | 0.00% | 17.70% | 17.97% |
| mono_imu_tum_vi_slides1 | 0.00% | 13.65% | 18.45% |
| mono_imu_euroc_MH01 | 0.00% | 21.18% | 30.21% |
| mono_imu_euroc_MH03 | 0.00% | 25.59% | 32.08% |
| meanTrackingTime | ori | fast | tbb |
|---|---|---|---|
| mono_tum1 | 0.00% | 8.32% | 17.86% |
| mono_tum2 | 0.00% | 9.83% | 13.68% |
| mono_tum_vi_room4 | 0.00% | 7.92% | 15.31% |
| mono_tum_vi_slides1 | 0.00% | 7.74% | 20.85% |
| mono_euroc_MH01 | 0.00% | 11.51% | 25.37% |
| mono_euroc_MH03 | 0.00% | 10.04% | 28.55% |
| mono_imu_tum_vi_room4 | 0.00% | 15.09% | 19.16% |
| mono_imu_tum_vi_slides1 | 0.00% | 10.84% | 21.94% |
| mono_imu_euroc_MH01 | 0.00% | 14.47% | 27.79% |
| mono_imu_euroc_MH03 | 0.00% | 12.50% | 35.30% |
总体:Slam-FAST稳定
分析:除了tbb的代码级别改造,Slam-FAST版本还有其他优化部分没增加完,在此基础上可以继续修改优化。
五、参考文献
[1] TBB官网:https://software.intel.com/content/www/us/en/develop/tools/threading-building-blocks.html
[2] Pro TBB: C++ Parallel Programming with Threading Building Blocks
https://book.douban.com/subject/35004080/
[3] TBB指令集c++并行化:https://www.bilibili.com/video/av508224172/