Keywords:
裂变传播、信息分发网络、深度复杂网络、高潜用户识别、关键意见领袖;
图算法社交网络关系挖掘、关键传播人群识别、关键意见领袖挖掘、PageRank & LeaderRank;
深度复杂网络传播模型;
一、概述
1.技术领域
主要应用方向涉及互联网中的用户社交网络信息传播、网络中关键路由节点识别等。
2.业界现状
互联网用户增长最重要的就是获客,通常是挖掘基于口碑/分享等行为带来新用户的优质老用户,帮助信息分发推广传播,提高信息传播效率和准确率,帮助高效地获取新用户。主要分析用户社交行为数据,以帮助获取新用户,提高信息推广效果。现有技术通常基于用户在社交网络分享带来新用户行为和日常购买行为,构建每个用户N级关系网络拓扑结构;提取用户行为特征,建立模型计算每个用户节点在关系网络的传播影响力评分,以给用户个性化推荐分发信息。
3.技术问题
当前技术仍旧存在一些问题:
1.常用做法没有将用户进行分层分簇处理,无法识别高效分发用户节点和分发效率较低的节点,只是给用户节点按统一权重优先级进行信息分发,整体信息分发效率不高;
2.整个用户网络的节点数量及连接边是动态更新的,若动态网络中信息传播按此一般方法处理,对于连接较少的边缘节点难以获取其真实信息分发影响力,因此存在冷启动问题,需要长时间迭代才能使网络稳定。
针对这些问题,我们提出了一种新方案,可以对这些问题进行改进:
1.原始数据预处理,利用主题模型将用户分层分簇,达到精细化目的,再在每个簇中基于多维度用户特征构建网络结构,从而构建整个连接网络。
2.对于新加入节点的冷启动问题,改进网络节点排名算法。第一,加入结合用户多维度特征的冷启动,有效避免新节点加入不能更快收敛的问题;第二,结合用户多维度特征,优化网络边计算权重公式,能更快更准确地发现网络高影响力节点。
二、技术方案
我们提出了一种信息分发网络中关键用户识别的算法。总体步骤如下:
1.通过用户多维度基础特征、社交网络活跃度特征,构建用户基础画像特征,利用模型综合评分,计算得到用户基础特征评分;
2.通过用户沟通文本挖掘,文本LDA主题聚类得到top主题簇及每个主题簇下的用户、和通过用户行为聚类得到用户簇。
3.通过用户社交网络分享/链接转发/关注/邀请等行为事件构建关系网络,生成图的邻接矩阵;历史转发分享行为事件的频率,作为特征,训练评分,用以修改网络边的权重;
4.计算网络每个节点的出度和连接边权重,得到每个节点的影响力分数,和用户基础特征的评分加权融合。在每个簇内,(1)节点按影响力分数由高到低排名,取Top-N作为关键信息分发节点用户;(2)按影响力分数排名取分位数划分得到高潜/中潜/低潜用户分档。
整体架构图如下:
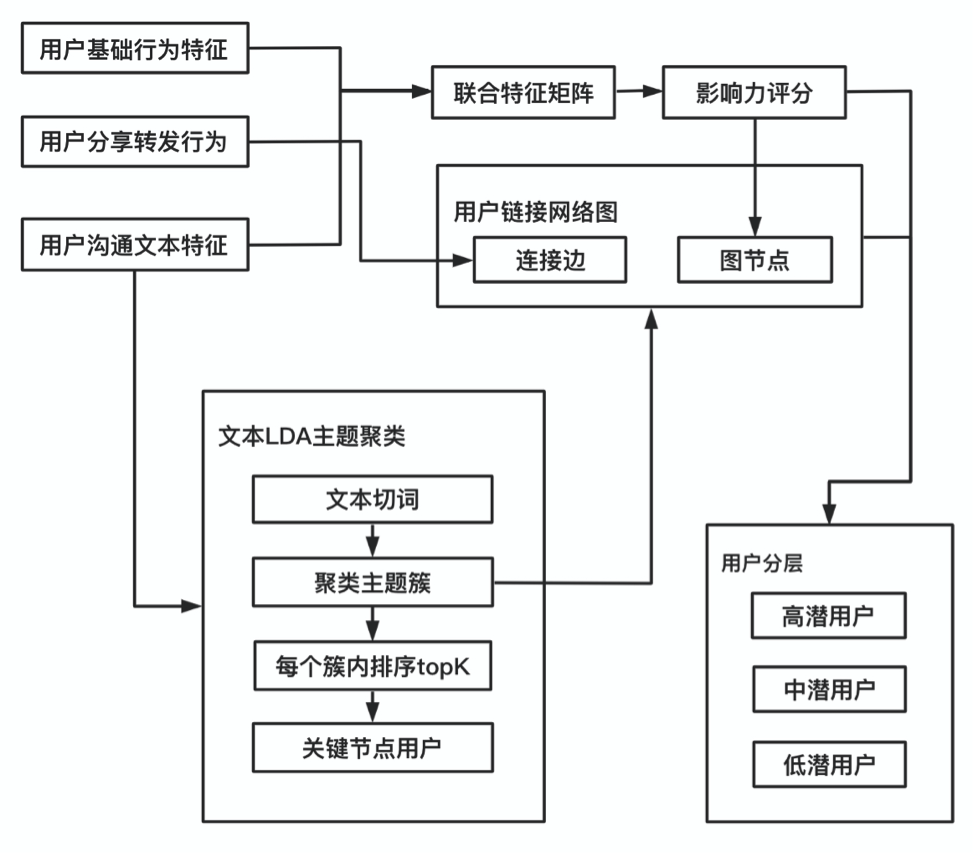
1.基础画像特征
多维度用户基础画像特征建模,将用户特征分为几大类,基于此构建特征矩阵。
- 产品质量体验类:产品使用率、复购率;反馈好/中/差次数;反馈次数、反馈满意/不满意次数;
- 利益折扣类:折扣敏感度、折扣金额、购买力;购买金额/累计购买金额、购买次数/累计购买次数;最近一次购买距现在时长;近半年购买数量;首次/末次购买时间;
- 积分成就类:用户是否会员、积分数、积分使用情况;会员、优惠券、积分、金币数量、钻石数量;
- 活跃因子类:用户登录行为(登录频率/登录时长)、浏览/点击/订单行为、用户微信活跃度、用户转发数、评论数;首次注册渠道/首次注册时间;近3/7/14/30/90天登陆app次数、近7/14/30天曝光次数、近7/14/30天点击次数;首次/末次登陆app时间;
- 用户基本属性类:用户画像(性格外向/内向、积极/消极、用户地理位置、用户城市及等级);性别、年龄、常驻省份、常驻城市、购买用户类型(RFM分层)
通过特征训练模型,得到用户评分,据此作为用户网络节点的影响力评分;
类比RFM分层融合评分,每维特征分层打分然后得到综合得分,由此网络图节点的多维度影响力评分的计算方式如下:
可得图节点归一化分数:
记录用户历史数据中每次分享转发、关注、邀请等行为,例如用户A转发分享信息到用户B,则节点A和B之间建立连接边,对于历史数据中A若有多次转发给B,则增加A到B边的权重评分。由此建立整个网络的连接边及边的权重weight。网络每次迭代更新边的权重。
连接边权重的计算公式,详见后4.3小节-改进网络节点排名算法,节点边权重因子归一化计算式。
2.文本挖掘和用户情感分析
2.1.文本预处理
通过用户在微信等主要社交app上的沟通文本,提取用户文本相关特征。
(1) 取历史定长时间窗口(例如三个月),将每个用户的沟通文本按时间序列聚合为一个长句子,考虑词序上下文关系,得到文本句子集合;
(2) 文本过滤:去除标点符号、特殊符号、数字、非法字符、表情包、链接;
(3) 文本句子分词,得到二元组2-gram、三元组3-gram、四元组4-gram、…;
(4) 去除停用词stop-words;
(5) 由词向量得到句子向量,(采用word2vec等方法进行词向量训练);并联合join上用户其他维度特征features;
2.2.用户情感分析
利用机器学习模型对用户文本进行二分类(积极正向/消极负向)。
模型:贝叶斯文本分类器、或梯度树模型GBDT等。
3.文本主题聚类
采用LDA主题模型对用户文本进行主题聚类,提取重要主题。主要为:第一,由文本提取出top主题;第二,获取每个主题下的词的分布;
(1)由文本聚类得到主题。文本切词,然后LDA聚类,得到topN主题。对于词个数太少(小于某个设定阈值)的簇,无法聚类为主题的,过滤掉。得到如下所示:
| 主题 | 词簇 |
|---|---|
| Topic 1 | [text1]: word1, word2, …, wordK |
| Topic 2 | [text2]: word2, word3, … , wordM |
| … | … |
| Topic N | [textN]: word5, word7, …, wordX |
(2)采用LDA主题模型训练,得到切词后每条文本,对应每个主题下的词的概率分布。如下所示:(表中数值为举例示意)
| prob | Topic 1 | Topic 2 | … | Topic N |
|---|---|---|---|---|
| Text 1 | 0.226 | 0.213 | … | 0.005 |
| Text 2 | 0.526 | 0.498 | … | 0.004 |
| … | … | … | … | … |
| Text M | 0.154 | 0.112 | … | 0.001 |
(3)上表中,每条文本关联上user_id列,得到每个用户-文本对应在每个topic下的概率。然后选每个用户下最大概率的topic作为用户当前所属的topic。
| user_id | text | topic |
|---|---|---|
| user_id 1 | text 1 | topic A |
| user_id 2 | text 2 | topic B |
| … | … | … |
| user_id M | text M | topic S |
(4)最终得到每个topic下的user_id集合(用户簇)。
| topic | user_id_set |
|---|---|
| topic A | user_id1, user_id3, user_id6, …, user_idN |
| topic B | user_id2, user_id5, user_id8, …, user_idT |
| … | … |
| topic N | user_id9, user_id13, user_id15, …, user_idX |
4.网络图节点排名
对于每个topic下的用户簇,识别该簇下的重要信息分发节点用户。
4.1.PageRank网络节点排名算法
PageRank作为基础算法,该网页排名算法来源于Google。其原理是依据网页被链接的数量,计算该网页的重要性排名,按权重PR值由高到低排名。(每个网页权重PR值迭代更新直到收敛。)
基本思路:
(1) 若某网页被很多其他网页链接到,则该网页重要,PR值提高;
(2) 若某网页被某PR值很高的网页链接到,则该网页的PR值提高;
定义:
- 出链:一个网络节点对外链接到其他网络节点;
- 入链:一个网络节点被其他外部节点链接到;
- 无出链:一个网络节点不链接其他网络节点;
- 只对自己出链:一个网络节点只链接给自身;
- PR值:依据网络节点的度,计算得到的评判分数;
以一个网络中有ABCD四个节点为例,所有网页(节点)链接都可以分为以下4种情况:
case1:节点都有出链。此时A节点PR值计算为:
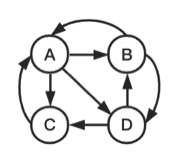 |
$$ PR(A)=\frac{PR(B)}{2}+\frac{PR(C)}{1} $$ |
case2:存在没有出链的节点。此时A节点PR值计算为:
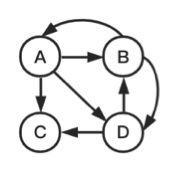 |
$$ PR(A) = \frac{PR(B)}{2}+\frac{PR(C)}{4} $$ |
节点C无出链,则其对A,B,D节点无PR值贡献。为了便于计算,对于没有出链的节点,强制设定让其对所有的节点都有出链,使得其对所有节点都有PR值贡献。
case3:存在只对自己出链的节点。则A节点PR值计算公式为:(其中$\alpha$一般取值0.85)
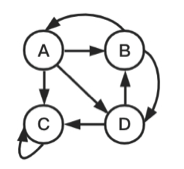 |
$$ PR(A)=\alpha(\frac{PR(B)}{2})+\frac{1-\alpha}{4} $$ |
节点C为只对自己出链的节点。进入网页节点C一般会继续跳转,因为只对C自己出链,故假设会重定向到其他任意网页节点。设定存在一定概率为$\alpha$会重定向到其他任意网页节点。
综上,单个节点的PR值一般计算公式:(其中,为有出链到的所有节点集合,为有节点的出链总数,$N$为节点总数,$\alpha$常量(一般0.85))
所有节点PR值一直迭代计算,直到以下两种情况之一发生即停止:1.每个节点的PR值前后误差小于自定义误差阈值;2.迭代次数超过自定义迭代次数阈值;
该算法缺点:对新加入节点不友好。一个新节点入链相对较少,即使其可能是潜在高链接节点,要达到高PR值需要长时间迭代。
4.2.LeaderRank网络节点排名算法
在PageRank基础上,LeaderRank是改进的网络节点排名算法。增加了全局公共节点Ground Node,此节点连接网络中全部节点。所以一个N节点M边的网络G(N,M)变成N+1节点M+2N边的网络G(N+1, M+2N)。
增加Ground Node的作用:
(1)因Ground Node连接了网络中所有节点,所以网络一定为连通图,保证了LeaderRank的收敛性,减小了整个网络半径,增加收敛速度。
(2)某i节点的信息来源(即由i节点发出的指向其余节点的边)的多少,反比于节点i流向Ground Node节点的个数。随着网络结构的变化,不同的节点会有不同的“跳转概率”,由此 LeaderRank算法不再需要参数“跳转概率c”。
LeaderRank算法公式:
其中,表示当前节点$j$是否有连接到节点$i$,为节点$j$指向其他节点的连接个数,为$i$节点在$t$时刻得分;为收敛时刻;为时刻$i$节点的得分;为时刻Ground Node节点的得分;为$i$节点最终得分;
4.3.改进的网络节点排名算法
基于两种算法本身存在的局限性问题,结合本场景的具体应用,做了如下改进:
1.加入节点冷启动处理。对于新加入的节点,节点边的权重计算:默认其对外连接和外部节点到该节点的连接初始化为0;节点本身分数计算:同基础特征计算方式,即前述的归一化分数计算值作为默认数值。
2.结合用户多维度特征,优化网络边计算权重公式,即网络图节点出度计算公式:
节点边权重因子归一化计算公式:
归一化分数,此表示节点$j$对外连接数,除以整个网络对外出度的边之和。
结合上述LeaderRank两个计算式,有网络图节点出度计算公式:
对于每个簇,计算每个用户节点的评分值和边权重值,用户基础评分特征分数加权融合。迭代更新,直至整个网络收敛。则有:
其中,为网络节点最终影响力分数,为当前节点$j$在当前$t$时刻节点评分值,为当前节点$j$对网络其他所有节点的出度边权重,对其求和得到所有出度边影响权重分数,为节点归一化影响力分数,即归一化分数的。此外,$\alpha$、$\beta$、$\gamma$ 分别为每个因子的加权融合的权重因子。
通过以上改进,该算法能更快更准确地发现网络高影响力节点。同时因为加入了多维度计算的冷启动,有效避免了新节点加入不能更快收敛的问题。
5.用户分层结果输出
每个簇中的用户节点,按综合因子评分由高到低排序,截取topK作为关键信息分发用户节点。(排名越高,该特征属性的权重分数越高)
排序用户中,用户结果分层,按分位数分为:高潜用户、中潜用户、低潜用户,作为结果输出。
三、小结
新的算法有很多优势:
1.能对新加入的或者比较冷门的节点基于用户特征进行预处理,能更快促使网络收敛。
2.将用户分层分簇之后对每个网络计算,使结果更精细化。
3.大部分是基于已有历史用户数据建立网络,能识别哪些历史用户是关键节点,对于新加入网络的节点相对不太容易发现高可能性信息分发用户节点。
四、名词解释
1.PageRank:网页排名算法,由网页之间相互的超链接计算网页评分值,体现网页的相关性和重要性,常用于搜索引擎优化。通过网页链接关系来定一个页面的等级。
2.LeaderRank:对PageRank网页排名算法的改进算法。通过在网络中增加一个节点,将其与网络中的所有节点相连,得到一个强连接的新网络。根据公式不断进行迭代,直到达到稳定状态,能保证网络快速收敛。